The story of cloud computing
It all began with a physical server. If you had a website and you wanted to release it onto the world wide web you needed to build it on a physical server in your basement or in the office or somewhere physically near you. This physical server contained memory, CPU, storage adapters, and network adapters. All of this was held together by an operating system. On this physical server, you could run a lot of applications. Think Mission Impossible. In the early movies, Tom Cruise always has to go disguise himself, run very fast to a physical place, and mess with a physical server in order to save the world. The physical server was a thing Ethan Hunt could find and reconfigure.

Monolithic architecture
When software was just beginning (on physical servers that Ethan Hunt could find and reconfigure), it was built using a traditional, monolithic architecture.
What is monolithic architecture?
-
Includes everything that an application needs to run, all tightly integrated. Include things like:
-
Database
-
Web interface
-
Shared libraries
-
Reporting tools
-
More often than not (but not always), applications are written in the same language
-
Everything needs to be configured to work with the same operating system

That sounds great, right? You have all of your important items together! You make an update and it’s all done. You don’t have to worry about a bunch of random little pieces!
Advantages of a monolithic architecture:
-
Easy to develop
-
Easy to deploy
-
Easy to manage
Disadvantages of Monolithic architecture:
-
Complex, not very resilient:
-
What if your database breaks and you need to fix it? You can’t fix it without simultaneously messing with the whole system. Suddenly, everything in your application is not working because one of the tightly coupled pieces doesn’t work.
-
Hard to debug:
-
What if you want to fix your web interface and adjust your libraries? You release the changes simultaneously, but your website goes down after the deployment. Now you don’t know what happened.
So, how can we make this architecture more manageable? We want to create software that is more resilient and flexible! But how can we do that when we’re tied to one physical server that some guy in a disguise who runs very fast can mess with?
Transition to services
Running an application on a physical server has a few problems. First, you’re limited to that server's memory, CPU, and storage. You’re also limited by the location of that specific server.
Most applications are not static. People use websites and applications throughout the day, and behavior changes across time. Here’s an example of why this inconsistency is important:
Let’s say you run a company that sells tickets to events. Your primary customers are in North America, but you have some customers in Europe and Asia. Right now you have a physical server in Virginia that is sized for the volume of your ticketing system. You have enough memory, CPU etc… to successfully run your database, web interface, reporting tools, etc… In other words, you’ve sized it perfectly.
Let’s say that Taylor Swift suddenly announces that she is going on tour across the entire globe! And–Taylor is going to sell her tickets exclusively on your site! Suddenly your physical server that’s been perfectly sized to fit your software will be super overwhelmed by incoming traffic. You’ll have people from all over the globe adding tickets to their carts, visiting the homepage, and entering their credit cards. You’ll max out of everything–memory, CPU, storage!
You have some time before the tickets go on sale. You have a few choices. You can scale vertically or horizontally.
-
Vertical scaling:
-
This means adding to the same physical server. You’ll give it more memory, CPU, and everything.
-
Horizontal scaling:
-
Horizontal scaling means that instead of building on the same physical server, you create more machines or “nodes” to handle the workload.
Scaling horizontally makes more sense for your ticketing company because you can build out servers across the globe to help support traffic in India, Ireland, and Brazil. You can build your architecture so that if more people are browsing the site but not buying, the application that collects payment doesn’t have as many resources as the application that runs the web interface. Suddenly, you don’t just have a single server that Ethan Hunt can destroy; you’re spread across the entire world!
But how does this happen? How can you take your ticketing app and break it up into little pieces? The answer is service-oriented architecture or microservices.
Service-oriented architecture
A monolithic architecture is designed, built, and deployed as a single entity. Service-oriented architecture is the opposite. Instead of thinking of an organization as a whole, a SOA is designed from the beginning with sharing capabilities in mind. Think of the monolith as a big island, like Pangea, but it was broken up into smaller parts that became separate continents like South America, Africa, and North America. Imagine that each smaller continent has its own language. However, these continents with unique languages can still speak to each other using an API. You can think of an API as a translator that helps connect one language to another.
In the example of our ticketing system, each application that made up our monolithic architecture would become its own independent service.
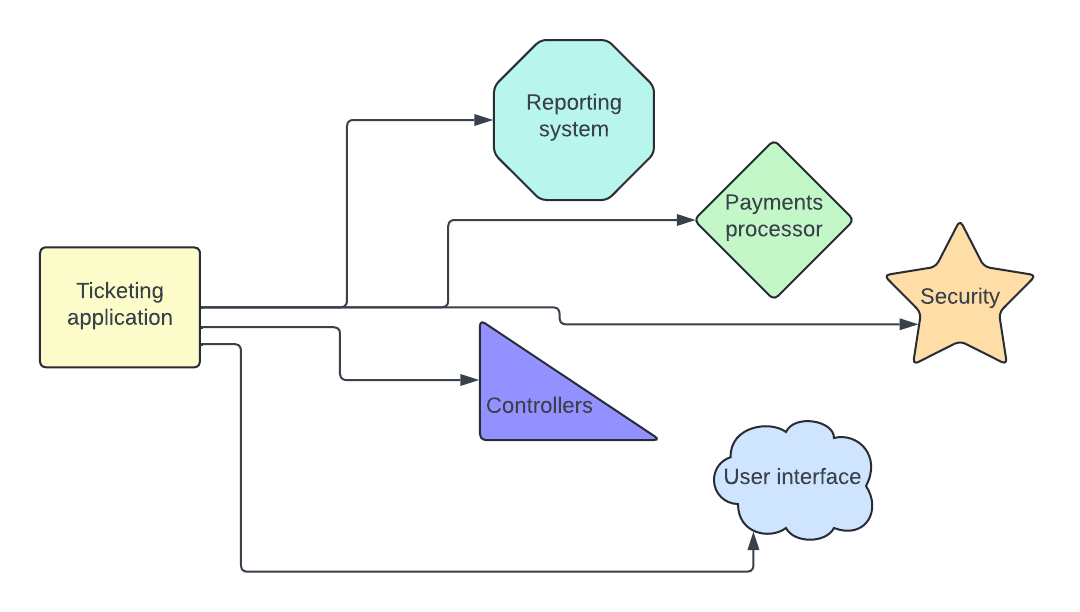
Microservices
Microservices are a step beyond service-oriented architecture. They take one of those applications and isolate their different functions, then create small chunks of code that isolate one specific function. Each function can be written in their own language.
For the ticketing example, imagine that you have two engineers who work on the payments system. The payment application has a bunch of smaller pieces. One authorizes payments, and one captures payments. One of your engineers loves Ruby, and the other loves Python. With microservices, they can each build their application in their own language and use an API to connect the two.
With microservices, you can also build extra instances of each service to match demand. So, with the Taylor Swift concert example, when it comes time for her to launch her tour, you can scale up the payment service horizontally automatically.
Benefits of microservices:
-
If a service fails, the rest of the application is still functional
-
Easy to scale
-
Easy to iterate
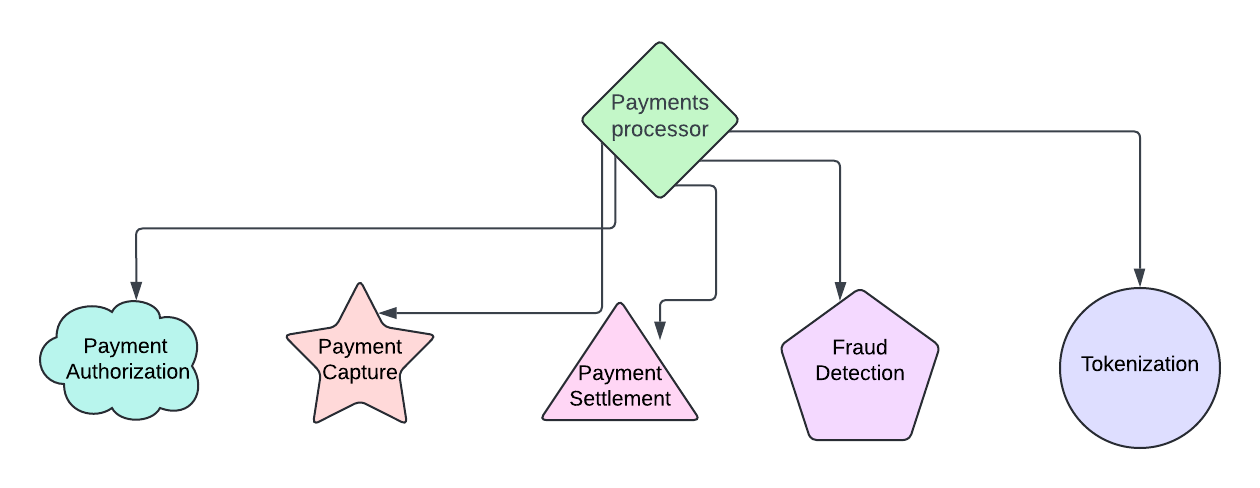
Virtual machines
Virtual machines were invented by IBM in the 60’s. Remember Ethan Hunt’s Mission Impossible physical server? A virtual machine transforms the physical server into a host containing various virtual machines with independent operating systems. Think about it like a big computer containing a bunch of minicomputers. Virtual machines were originally designed to help multiple users share the same physical application. They also helped improve testing and development, and reduce costs.
Now, virtual machines are the backbone of service-oriented architectures and microservices. Yes, SOA and microservice applications can still run on bare metal servers, VMs just make everything easier.
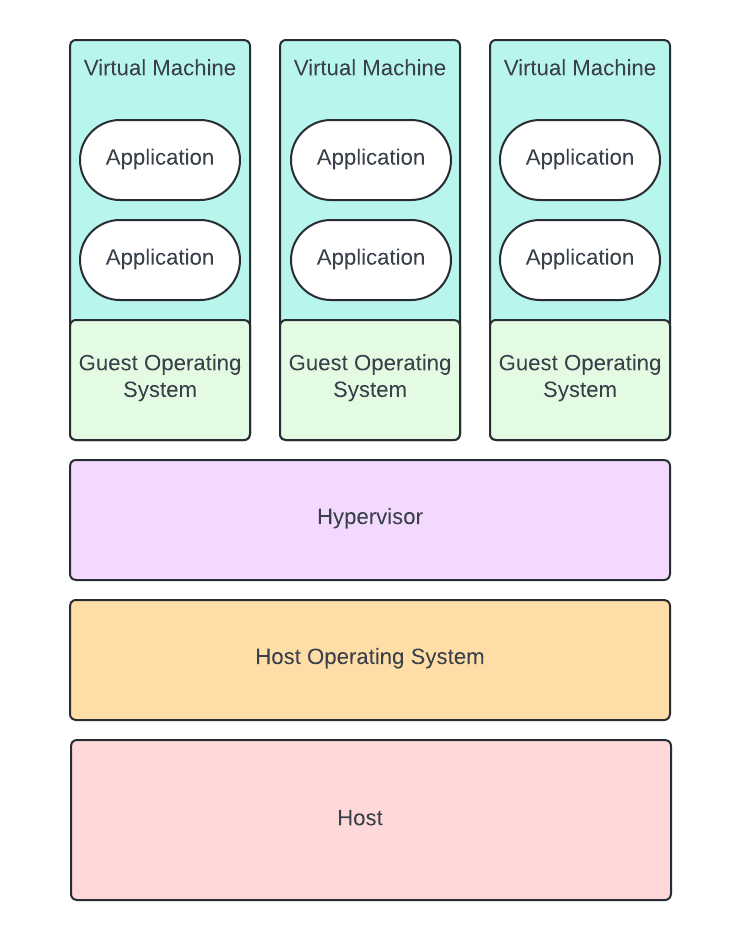
These virtual machines still run on the same physical server but instead of installing an operating system on the physical server, like Linux, we will install a hypervisor. It is basically the conductor. It connects the virtual machines to the physical resources on the physical server. It’s the brain that dictates where the resources are going to go (like memory and CPU).
There are two types of hypervisors:
-
Type 1 or Bare metal hypervisor is one that you install on the physical server, like:
-
VMware EXSI
-
Microsoft Hyper-v
-
Type 2: A hypervisor installed directly on your computer. It is running on top of an operating system, like:
-
VMware Player
-
VMware Workstation
Benefits of virtualization:
-
Portability: Because each VM contains its own operating system, you can easily move a VM from one hypervisor to another.
-
Saves you money!: You can consolidate your applications onto on physical server
-
Resiliency: If one host goes down, you can easily move it.
Truths about the cloud
Theoretically, even if you were running your application on a virtual machine, you could still track down a server and reconfigure it like Ethan Hunt. AWS, for example, hosts many virtual machines, and you could go to their server sites and find the one that’s hosting a specific virtual machine, but it would be a lot harder to find.
-
Even though it’s a “cloud,” it is still grounded on the earth. There are still physical servers all around the world that host the “cloud.”
-
If one of those physical servers fails because of a very real physical problem, like a power outage or a hurricane where that physical server lives, your applications can still run because you can spread your application across physical servers.
Why would it be harder for Ethan Hunt to track down the physical server that's hosting the virtual machine that is running your application? Because of load balancing, zones, and regions!
AWS EC2 (to be continued)